Alejandro Navas González has been working for four years in data science and bioinformatics. He has experience in coding, modification, testing, and implementation of business technology solutions, and knowledge of statistical and graphical methods for data analysis.
Professional Experience
Intrum - Data Scientist
April 2022 - October 2024
As a Data Scientist at Intrum, Europe’s leading debt collection firm, I spearhead data-driven projects to optimize performance across various departments, notably in Call Center operations. My work focuses on creating and implementing models that enhance the efficiency and decision-making processes in debt collection and agent performance. By leveraging tools like SQL, Python and R, I provide actionable insights that directly impact company-wide strategies and operational success.
Key Achievements:
- Developed predictive models that improved call center efficiency.
- Automated debt recovery workflows, reducing manual intervention.
CGI Group Inc. - Data Scientist
September 2021 - April 2022
At CGI, I was part of the cross-functional support team, working on large-scale data projects for Banco Santander. Utilizing Big Data technologies such as Apache Hive and Python libraries like pyspark, I helped analyze vast data lakes to derive insights that improved operational strategies and compliance for the banking sector.
Key Achievements:
- Led efforts in data cleaning and preprocessing, ensuring high-quality datasets for accurate analysis and model building.
- Enhanced data processing pipelines that led to an increase in query performance.
M2C Consulting - Systems Architect
March 2021 - September 2021
In my role as Systems Architect at M2C Consulting, I was responsible for designing and optimizing applications for Mutua Madrileña in the insurance domain. I led the development of system architectures using Pegasystems software, ensuring scalability, security, and efficiency in application workflows.
Key Achievements:
- Architected a new claims management system.
- Integrated automated reporting tools, streamlining data collection.
HelixBioS - Bioinformatician
January 2020 - July 2020
At HelixBioS, I specialized in microbiome analysis, focusing on the ecological relationships within microbial communities. I developed advanced graphical and regression models to analyze Rhizosphere rRNA16 samples from various studies. Using tools such as R and its bioinformatics packages, I provided insights into microbial interactions and contributed to key research in ecological microbiology.
Key Achievements
- Constructed network models that revealed new microbial interactions, furthering the understanding of soil ecosystems.
- Published comprehensive analysis reports that contributed to ongoing research in the field of microbiome studies.
Education
Master’s degree in Big Data & Business Analytics
Universidad Complutense de Madrid | Madrid, España | 2021-2022
Master’s degree in Bioinformatics & Biostatistics
Open University of Catalonia | Madrid, España | 2019-2020
Degree in Biotechnology
Universidad Politécnica de Madrid | Madrid, España | 2015-2019
Tools Knowledge
Data Analysis & Visualization: R (tidyverse, ggbetweenstats), Python (pandas, matplotlib, seaborn), Excel
Machine Learning & Statistical Modeling: R (caret, H2O, naivebayes, sparklyr), Python (scikit-learn, tensorflow, keras)
Big Data & Distributed Computing: Python (pyspark), R (sparklyr), SQL (Impala, MySQL)
Bioinformatics & Computational Biology: R (phyloseq, vegan, igraph), Usearch, Systems Biology tools
Automation & Reporting: R (rmarkdown, plumber), Python (LaTeX), RMarkdown
Web Development & Interactive Dashboards: R (shiny, shinydashboard, fresh), Tableau, PowerBI, HTML, CSS
Certifications
Datacamp
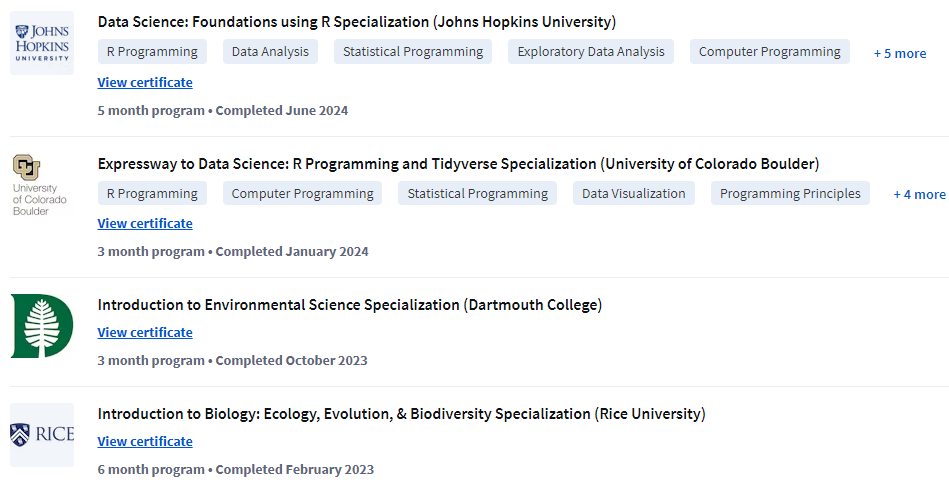
Coursera
Kaggle